Chapter 25 Multiple Regression Analysis
25.1 Intro
Multivariate regression analysis can be useful to obtain a model to predict the dependent variable as a function of two or more predictor variables and estimate what proportion of the variance of that dependent variable can be understood using the predictor variables. The approach differs for continuous or categorical predictors, and both will be shown.
25.1.1 Example dataset
This example uses the Rosetta Stats example dataset “pp15” (see Chapter 1 for information about the datasets and Chapter 3 for an explanation of how to load datasets).
25.1.2 Variable(s)
From this dataset, this example uses variables xtcUseDosePref as dependent variable (the MDMA dose a participant prefers), highDose_attitude, highDose_perceivedNorm, and highDose_pbc as continuous predictors (the attitude, perceived norms, and perceived behavior control with respect to using a high dose of MDMA), and hasJob_bi as a categorical predictor (whether a participant has a job or not (e.g. is a student or unemployed)).
25.2 Input: jamovi
In the “Analyses” tab, click the “Regression” button and from the menu that appears, select “Linear Regression” as shown in Figure 24.1.
Figure 25.1: Opening the linear regression menu in jamovi
In the box at the left, select the dependent variable and move it to the box labelled “Dependent variable” using the button labelled with the rightward-pointing arrow as shown in Figure 24.2.
Figure 25.2: Selecting the dependent variable for the regression analysis in jamovi
In the box at the left, select the continuous predictors and move them to the box labelled “Covariates” using the button labelled with the rightward-pointing arrow as shown in Figure 25.3.
Figure 25.3: Selecting the continuous predictros for the regression analysis in jamovi
Categorical predictors are moved to the box labelled “Factors” instead as shown in Figure 25.4.
Figure 25.4: Selecting the categorical predictors for the regression analysis in jamovi
The results will immediately be shown in the right-hand “Results” panel. You can scroll down to specify additional analyses, for example to order more details about the coefficients by opening the “Model Coefficients” section as shown in Figure 25.5.
Figure 25.5: Opening the Model Coefficients section in jamovi
For example, to request the confidence interval for the coefficient and the standardized (scaled) coefficients, check the corresponding check boxes as shown in Figure 25.6.
Figure 25.6: Selecting the predictor for the regression analysis in jamovi
25.3 Input: R
25.3.1 R: base R
In base R, the lm (linear model) function can be combined with the summary function to show the most important results. With a continuous predictor, the code is as follows. R automatically treats variables that are factors as categorical, and numeric vectors as continuous variables.
result <-
lm(
xtcUseDosePref ~
highDose_attitude +
highDose_perceivedNorm +
highDose_pbc +
hasJob_bi,
data=dat
);
summary(
result
);25.3.2 R: rosetta
In the rosetta package, the regr function wraps base R’s lm function to present output similar to that provided by other statistics programs in one command.
rosetta::regr(
xtcUseDosePref ~
highDose_attitude +
highDose_perceivedNorm +
highDose_pbc +
hasJob_bi,
data=dat
);Like lm in base R, the command is the same for a continuous predictor as it is for a categorical predictor. Additional output can be requested using arguments collinearity=TRUE, and when there are two predictors and an interaction term, plot=TRUE):
rosetta::regr(
xtcUseDosePref ~
highDose_attitude +
hasJob_bi +
highDose_attitude:hasJob_bi,
data=dat,
collinearity=TRUE,
plot=TRUE
);25.4 Input: SPSS
In SPSS, the REGRESSION command is used (don’t forget the period at the end (.), the command terminator):
REGRESSION
/STATISTICS COEFF OUTS CI(95) R ANOVA
/DEPENDENT xtcUseDosePref
/METHOD=ENTER highDose_attitude highDose_perceivedNorm highDose_pbc hasJob_bi.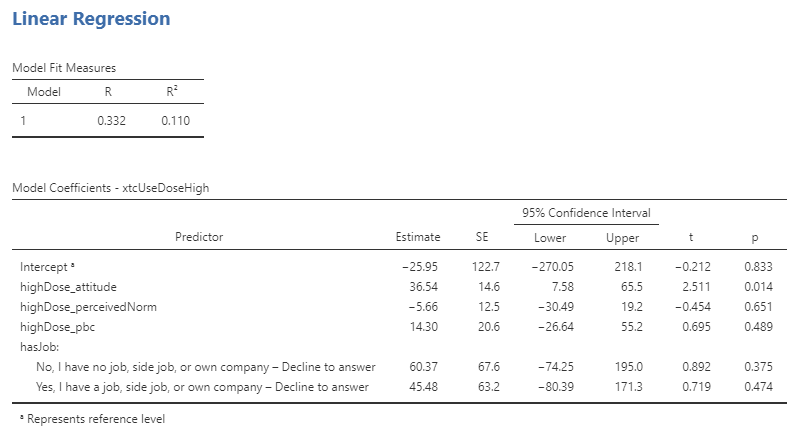
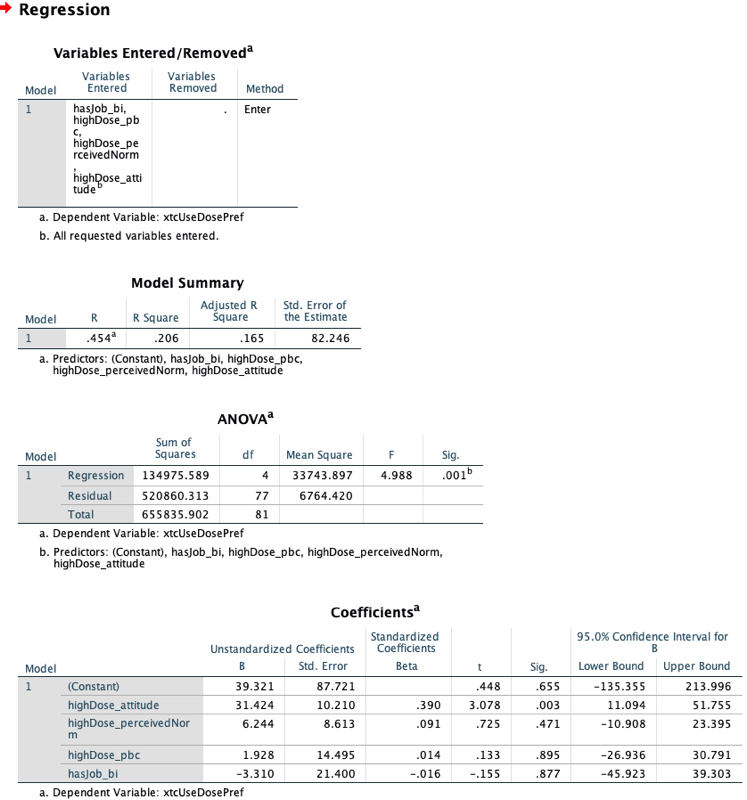
25.6 Output: R
25.6.1 R: base R
Call:
lm(formula = xtcUseDosePref ~ highDose_attitude + highDose_perceivedNorm +
highDose_pbc + hasJob_bi, data = pp15)
Residuals:
Min 1Q Median 3Q Max
-136.90 -48.76 -8.61 37.55 341.33
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 36.011 80.152 0.449 0.65449
highDose_attitude 31.424 10.210 3.078 0.00289 **
highDose_perceivedNorm 6.244 8.613 0.725 0.47072
highDose_pbc 1.928 14.495 0.133 0.89456
hasJob_biYes -3.310 21.400 -0.155 0.87750
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 82.25 on 77 degrees of freedom
(747 observations deleted due to missingness)
Multiple R-squared: 0.2058, Adjusted R-squared: 0.1646
F-statistic: 4.988 on 4 and 77 DF, p-value: 0.00125225.6.2 R: rosetta
## there are higher-order terms (interactions) in this model
## consider setting type = 'predictor'; see ?vif
## there are higher-order terms (interactions) in this model
## consider setting type = 'predictor'; see ?vif25.6.2.1 Regression analysis
Summary
| Formula: | xtcUseDosePref ~ highDose_attitude + hasJob_bi + highDose_attitude:hasJob_bi |
| Sample size: | 82 |
| Multiple R-squared: | [.07; .37] (point estimate = 0.2, adjusted = 0.17) |
|
Test for significance: (of full model) |
F[3, 78] = 6.69, p < .001 |
Raw regression coefficients
| 95% conf. int. | estimate | se | t | p | |
|---|---|---|---|---|---|
| (Intercept) | [-41.36; 216.05] | 87.34 | 64.65 | 1.35 | .181 |
| highDose_attitude | [-9.46; 60.68] | 25.61 | 17.62 | 1.45 | .150 |
| hasJob_biYes | [-196.13; 93.09] | -51.52 | 72.64 | -0.71 | .480 |
| highDose_attitude:hasJob_biYes | [-26.45; 52.66] | 13.11 | 19.87 | 0.66 | .511 |
| a These are unstandardized beta values, called ‘B’ in SPSS. |
Scaled regression coefficients
| 95% conf. int. | estimate | se | t | p | |
|---|---|---|---|---|---|
| (Intercept) | [-0.22; 0.51] | 0.14 | 0.18 | 0.78 | .436 |
| highDose_attitude | [-0.1; 0.65] | 0.28 | 0.19 | 1.45 | .150 |
| hasJob_biYes | [-0.46; 0.38] | -0.04 | 0.21 | -0.18 | .857 |
| highDose_attitude:hasJob_biYes | [-0.29; 0.57] | 0.14 | 0.21 | 0.66 | .511 |
| a These are standardized beta values, called ‘Beta’ in SPSS. |
Collinearity diagnostics
| VIF | Tolerance | |
|---|---|---|
| highDose_attitude | 4.68 | 0.21 |
| hasJob_bi | 11.93 | 0.08 |
| highDose_attitude:hasJob_bi | 15.13 | 0.07 |
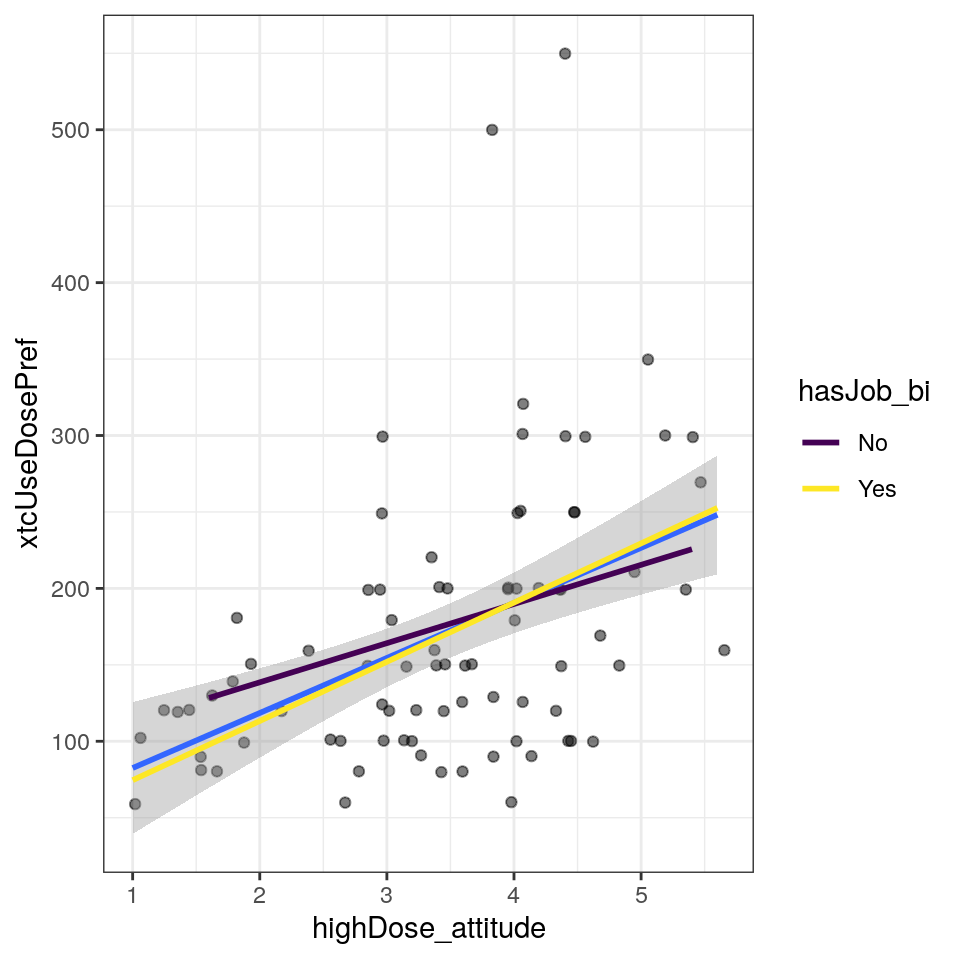
Figure 25.8: Scatterplot with regression line